序列化
java序列化机制Serialize接口
java本身的序列化机制存在的问题
序列化结果是二进制数据,不利于查看
- 序列化数据结果比较大、传输效率比较低
- 不能跨语言对接,只能java自己使用
xml
以至于在后来的很长一段时间,基于XML格式编码的对象序列化机制成为了主流,一方面解决了多语言兼容问题,另一方面比二进制的序列化方式更容易理解。以至于基于XML的SOAP协议及对应的WebService框架在很长一段时间内成为各个主流开发语言的必备的技术。
json
再到后来,基于JSON的简单文本格式编码的HTTP REST接口又基本上取代了复杂的Web Service接口,成为分布式架构中远程通信的首要选择。
但是JSON序列化存储占用的空间大、性能低等问题,同时移动客户端应用需要更高效的传输数据来提升用户体验。在这种情况下与语言无关并且搞笑的二进制编码协议就成为了大家追求的热点技术之一。首先诞生的一个开源的二进制序列化框架-MessagePack。它比google的Protocol Buffers出现得还要早
恰当的序列化协议不仅可以提高系统的通用性、强壮型、安全性、优化性能。同时还能让系统更加易于调试和扩展
恰当的序列化协议不仅可以调高系统的通用性、强壮型、安全性、优化性能。同时还能让系统更加易于调试和扩展。
序列化和反序列化的概念
把对象转化为字节序列的过程称之为对象的序列化
反之,称之为反序列化
怎么去实现一个序列化操作
- 实现Serializable接口
- ObjectOutputStream :把对象转换成二进制数据
- ObjectInputStream : 表示读取指定的字节数据转换成对象
1 |
|
1 | public class SerializeDemo { |
扩展疑问
serialVersionUID 作用
能够保证序列化的对象和反序列化以后的对象是同一个对象
serialVersionUID适用于Java的序列化机制。简单来说,Java的序列化机制是通过判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是InvalidCastException。
具体的序列化过程是这样的:序列化操作的时候系统会把当前类的serialVersionUID写入到序列化文件中,当反序列化时系统会去检测文件中的serialVersionUID,判断它是否与当前类的serialVersionUID一致,如果一致就说明序列化类的版本与当前类版本是一样的,可以反序列化成功,否则失败。
serialVersionUID有两种显示的生成方式:
一是默认的1L,比如:
1 | private static final long serialVersionUID = 1L; |
二是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段,比如:
1 | private static final long serialVersionUID = xxxxL; |
当实现java.io.Serializable接口的类没有显式地定义一个serialVersionUID变量时候,Java序列化机制会根据编译的Class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,如果Class文件(类名,方法明等)没有发生变化(增加空格,换行,增加注释等等),就算再编译多次,serialVersionUID也不会变化的。
如果我们不希望通过编译来强制划分软件版本,即实现序列化接口的实体能够兼容先前版本,就需要显式地定义一个名为serialVersionUID,类型为long的变量,不修改这个变量值的序列化实体都可以相互进行串行化和反串行化。
说白了就是一个class文件的一个版本号,类似文件的MD5值,只有两个值一直才能反序列化
静态变量的序列化
序列化并不保存静态变量的状态
transient 关键字
transient 关键字表示指定属性不参与序列化
父子类问题
如果父类没有实现序列化,而子类实现列序列化。那么父类中的成员没办法做序列化操作
序列胡的存储规则
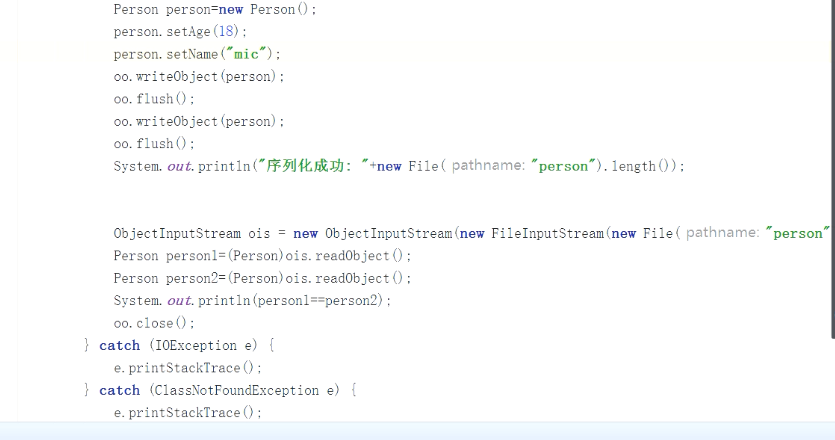
对同一个对象进行追加序列化,而是在原有的序列化对相中,添加5个字节的引用,并不会导致文件的累加。

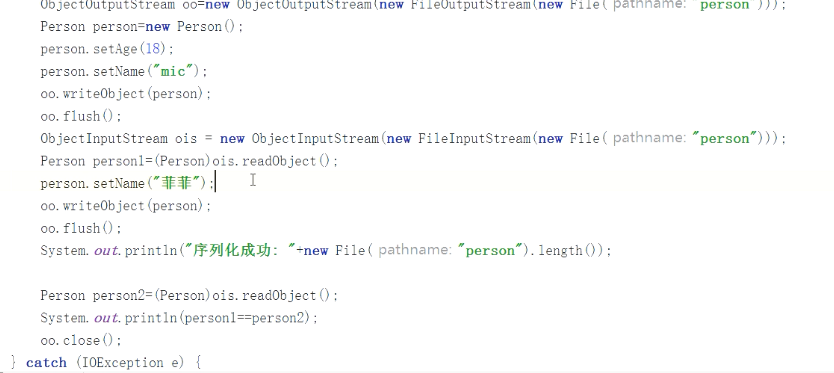
对同一个对象进行追加序列化,但是两个对象的属性值不一样,序列化对象不会翻倍,而是把变更的属性进行记录。

序列化的应用
实现深度克隆,无需实现Cloneable接口
- 浅克隆:拷贝复制对象,不复制对象的引用
- 深克隆:复制对象,同时复制引用的对象
总结
- 在java中,只要一个类实现了java.io.Serializable接口,name他就可以被序列化
- 通过ObjectOutputStream 和 ObjectInputStream 对对象进行序列化和反序列化操作
- 对象是否允许被序列化,不仅仅是取决于类对象的代码是否一致,通知还有一个重要的因素(UID)
- 序列化不保存静态变量
- 要想父类也参与序列化操作,则必须让父类也实现Serializable接口
- transient关键字,主要控制变量是否能够被序列化,如果没有被序列化的成员变量,反序列化后会被设置成初始值(基本数据类型的初始值,如int = 0, String = null)
- 通过序列化操作实现深度克隆
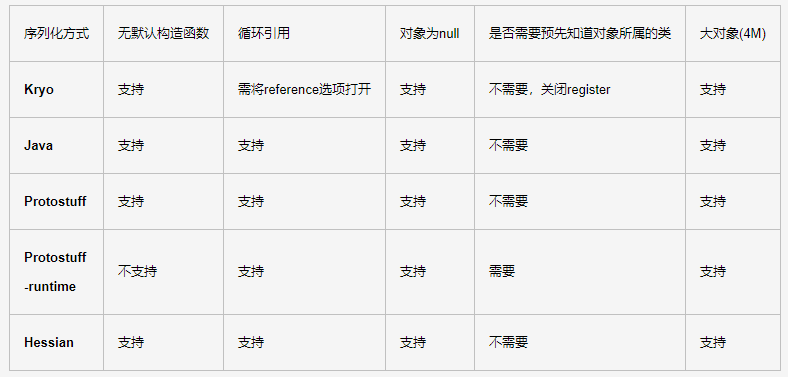
主流的序列化技术
- json
- Hessian (2)
- xml
- protobuf
- kryo
- MsgPack
- FST
- thrift
- protostuff
- Avro
性能对比
时间
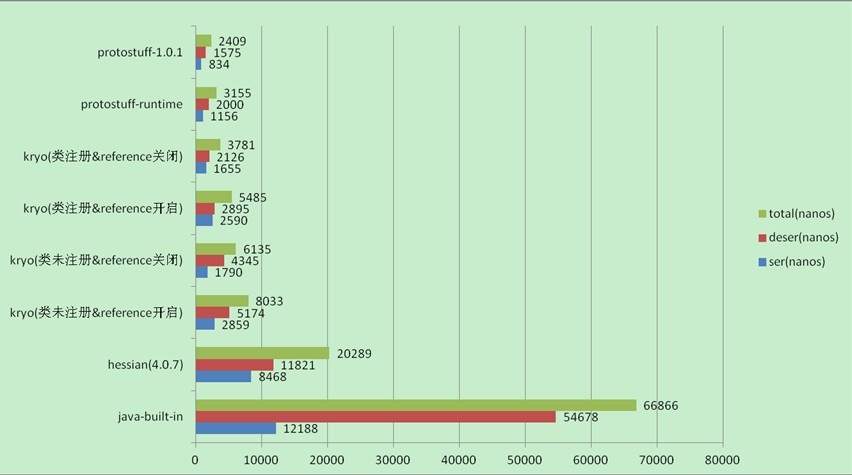
大小
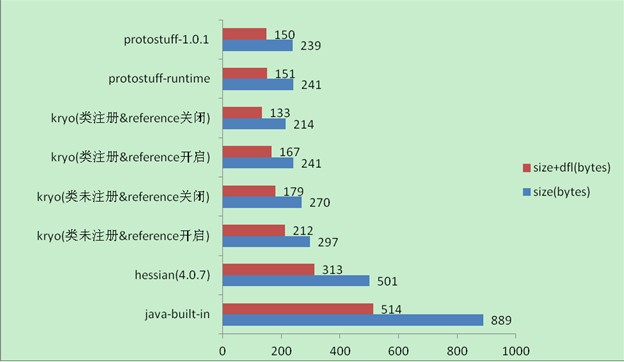
稳定性